已经收集了超过23万种化合物的各种性质的150多万个数据点,用以建立可靠的计算模型。在使用数据建模之前,对收集的数据进行了系统的筛选,以确保得到可靠的数据点。数据精选程序包括基本分析、统计过滤和相似性分析,下面以常沸点为例进行描述。
在常沸点的案例中,从111278个不同来源收集了52811个化合物的182526个数据点,包括期刊文章、科学书籍和专利。下图给出了所有收集数据的整体扫描:
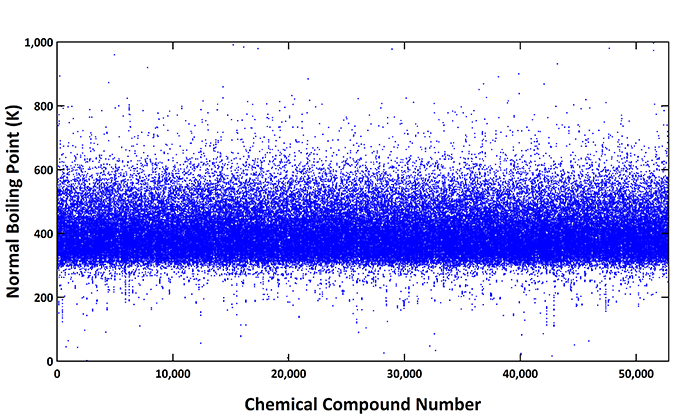 图1. 收集的52811个化合物(182526个数据点)的常沸点扫描
图1. 收集的52811个化合物(182526个数据点)的常沸点扫描
此图表显示了 52,811 个化合物中每 600 种的开尔文(K)温度的182,526 个数据点,这些数据点按沸点值升序排序。可以观察到大多数值分布在 300 到 600 K 之间
基本分析
由于数据来自许多不同的来源,单个化合物存在多个沸点。下表显示了每种化合物收集的数据点数量,以甲醇为例,数据点数量高达259点。
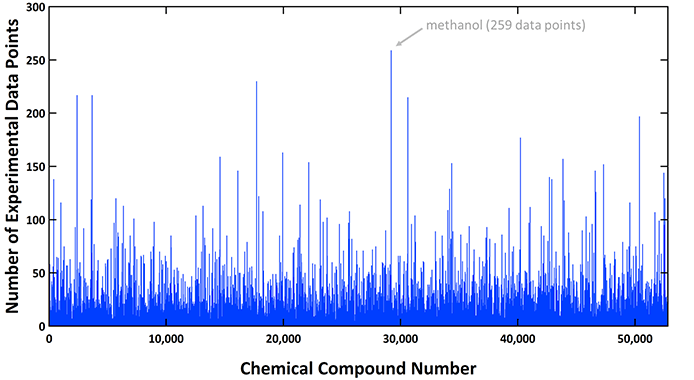 图2. 52811个化合物中每个化合物收集的常沸点数量
图2. 52811个化合物中每个化合物收集的常沸点数量
虽然常沸点被定义为每种化合物的单一值,但所收集数据的偏差往往是显著的。下图显示了之前扫描图放大后,从第5000个化合物到第6000个化合物的每个化合物的常沸点的偏差。对于每个化合物,最小点和最大点表示为小水平条,它们由表示偏差大小的垂直线连接。
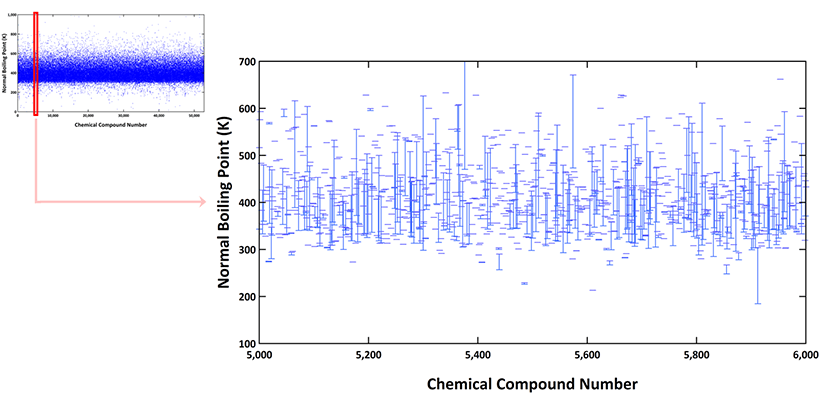 图3. 第5000个到第6000个化合物之间收集的常沸点的最小值/最大值
图3. 第5000个到第6000个化合物之间收集的常沸点的最小值/最大值
在52811个化合物案例中,分析每个化合物的偏差百分比,即{(max–min)/max}x100,从0.002到99.9%。整个52811个案例的平均偏差经计算为16.37%,标准偏差估算为13.48%。如果在一个固定实验室测量常沸点,这个水平的偏差明显高于报告的2%的实验误差。
因此,通过调查如何确定收集到的数据,详细分析了数据的来源。排除任何预测/估计的数据或在不同实验条件下测定的数据。
统计过滤
对每个化合物待处理的多个数据点进行平均,如果该点与平均值的偏差超过一定百分比,例如20–30%,则消除该数据点。类似程序继续进行——再次对其余数据点进行平均,如果该点与更新平均值的偏差超过了略低一些的偏差百分比,例如15-25%,则删除该数据点。这个程序继续直到剩余数据点与更新平均值的所有偏差都在足够低的百分比内,例如5-15%。
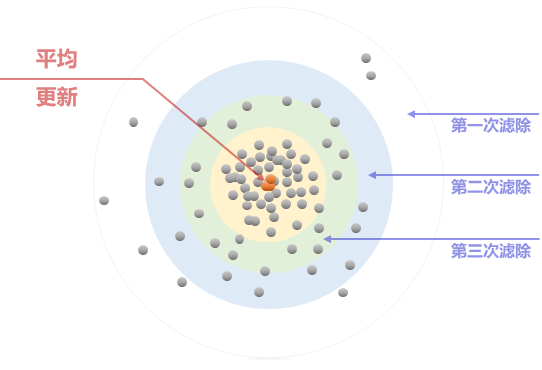 图4 . 统计过滤
图4 . 统计过滤
该程序是通过使用自主开发的计算机程序自动执行的。初始偏差百分比标准(以上文中提到的20–30%为例)、每个步骤的偏差百分比标准的减少(以上述的第二步15–25%为例)以及最终偏差百分比标准(以上述的5-15%为例)是根据每个步骤可用的数据点数量、每个步骤中各数据点的初始和更新偏差百分比以及每个步骤各数据的初始和更新平均值自动或手动确定的。
如果每个化合物的数据点数量不足,则此过滤程序不适用。如果每个化合物的可用数据数量足够大,该程序的主要目标是从统计角度消除明显不正确的数据。
相似性分析
“相似性分析”,就是利用经过过滤程序的数据点来确定每个化合物的可靠数据点。具有相似官能团或相似族的一系列化合物的常沸点被绘制出来,并生成了趋势曲线。然后,基于趋势曲线获得筛选的数据。
下表以正构烷烃的相似性分析为例进行了说明。统计过滤后的正构烷烃的沸点与碳原子个数呈函数关系,甲烷为1,乙烷为2,四碳烷为44
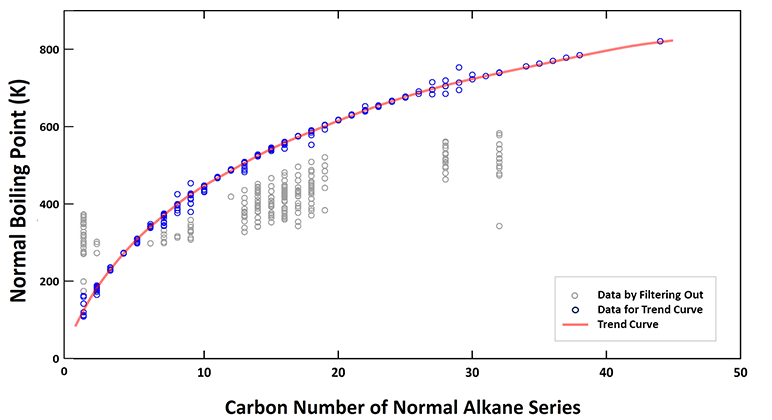 图5. 正构烷烃的实验常沸点与碳数的关系
图5. 正构烷烃的实验常沸点与碳数的关系
灰色的数据点通过过滤程序滤除,蓝色的点用于生成趋势曲线。根据趋势曲线得到每种烷烃的精确常沸点,该趋势线用于研究常沸点的性质。
获取趋势曲线并不总是那么简单。根据相似化合物的类型和相应的可用数据点,统计过滤和趋势曲线需要使用不同的偏差百分比标准迭代生成。
已经得出的结论是,任何公布的数据都可能有巨大误差。如果数据是估算的或是实测的,这些数据需要仔细核查。如果是实验数据,实验条件是什么。相同化合物的多个数据点以及相似化合物的数据都需要收集、分析和交叉检查,以确保数据的可靠性。